Add-it AI: Object Insertion in Images
A training-free approach that extends diffusion models to add objects into images based on text instructions. Achieve natural object placement with structural consistency while preserving original scene details.
What is Add-it AI?
Add-it AI represents a significant advancement in semantic image editing, specifically designed to address the challenge of adding objects into images based on text instructions. This innovative approach maintains a careful balance between preserving the original scene and integrating new objects in natural, fitting locations.
The system operates without requiring task-specific fine-tuning, making it accessible and efficient for users across various applications. Add-it AI extends diffusion models' attention mechanisms to incorporate information from three critical sources: the original scene image, the text prompt describing the desired addition, and the generated image itself.
This weighted extended-attention mechanism ensures that structural consistency and fine details are maintained while guaranteeing natural object placement. The result is a tool that can successfully add objects to both real photographs and AI-generated images with remarkable accuracy and realism.
Core Capabilities
- • Training-free object insertion
- • Natural object placement understanding
- • Structural consistency preservation
- • Works with real and generated images
- • Text-guided insertion process
- • State-of-the-art accuracy results
Technical Overview
Weighted Extended Self-Attention
The core innovation lies in the weighted extended self-attention mechanism that allows the model to consider information from multiple sources simultaneously. This approach ensures that the added object not only fits semantically but also maintains visual coherence with the existing scene elements.
Structure Transfer
Add-it AI employs sophisticated structure transfer techniques that analyze the spatial relationships and geometric constraints within the original image. This ensures that newly added objects respect the scene's perspective, lighting conditions, and spatial logic.
Subject Guided Latent Blending
The latent blending process is guided by subject-specific information, allowing for precise control over how the new object integrates with the existing scene. This technique preserves important details while ensuring smooth transitions between original and added elements.
Add-it AI Specifications
| Feature | Description |
|---|---|
| AI Name | Add-it AI |
| Category | Semantic Image Editing |
| Primary Function | Object Insertion in Images |
| Training Requirements | Training-Free Operation |
| Research Paper | arxiv.org/html/2411.07232 |
| GitHub Repository | github.com/NVlabs/addit |
| Interactive Demo | huggingface.co/spaces/nvidia/addit |
How to Use Add-it AI?
For Generated Images
Step 1: Source Prompt
Provide a detailed description of the base image you want to generate. For example: "A photo of a cat sitting on the couch"
Step 2: Target Prompt
Describe the desired final image including the new object. For example: "A photo of a cat wearing a red hat sitting on the couch"
Step 3: Subject Token
Specify the main object to be added using a single token that appears in your target prompt. In this case: "hat"
Step 4: Generate
Execute the process and receive your edited image with the object naturally integrated into the scene.
For Real Images
Step 1: Upload Image
Upload your existing photograph or image that you want to modify by adding objects to it.
Step 2: Describe Original
Provide a source prompt that accurately describes the current state of your uploaded image.
Step 3: Describe Target
Create a target prompt describing how the image should look after adding the desired object.
Step 4: Process
Let Add-it AI analyze the image and intelligently place the new object in the most appropriate location.
Key Features and Advantages
Training-Free Operation
No need for extensive training datasets or computational resources. Add-it AI works immediately with pretrained diffusion models, making it accessible for immediate use.
Affordance Understanding
The system demonstrates deep semantic knowledge of how objects interact with environments, ensuring realistic placement that follows natural rules and logic.
Structural Consistency
Maintains the original image's structural integrity while adding new elements, preserving perspective, lighting, and spatial relationships.
Fine Detail Preservation
Advanced attention mechanisms ensure that intricate details in both the original scene and added objects are maintained at high quality.
Multi-Source Integration
Intelligently combines information from the scene image, text prompt, and generated content to produce coherent, realistic results.
Benchmark Performance
Achieves state-of-the-art results on both real and generated image insertion benchmarks, preferred in over 80% of human evaluations.
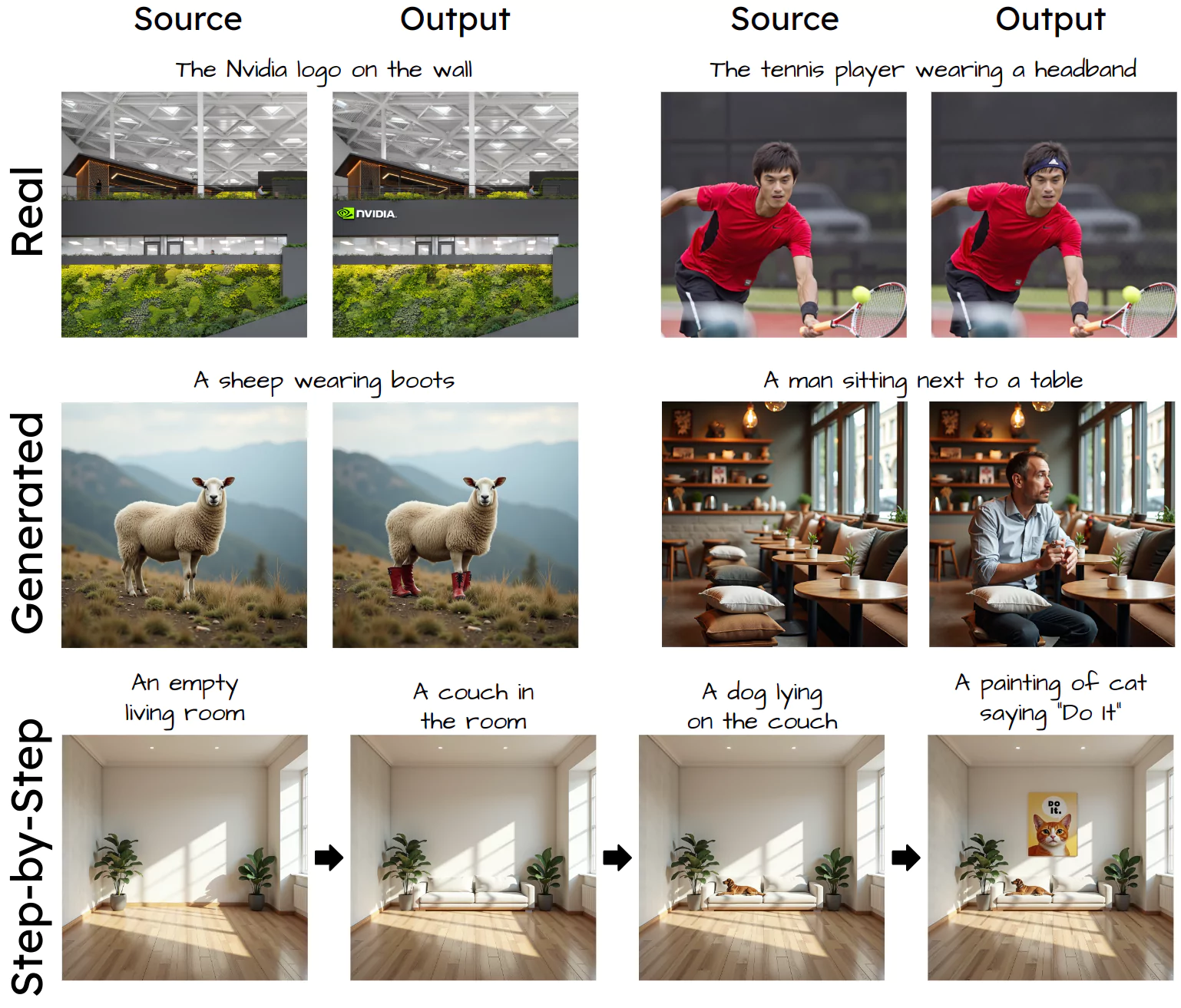
Visual Examples

Step-by-step visualization of Add-it AI's object insertion process

Add-it AI's capability with non-photorealistic images
Real-World Applications
Content Creation and Marketing
Digital marketers and content creators can efficiently add products, accessories, or environmental elements to existing photographs without complex photo editing skills. This enables rapid prototyping of marketing materials and social media content.
E-commerce and Product Visualization
Online retailers can add products to lifestyle images, showing how items would look in real environments. This helps customers visualize products in context, potentially increasing engagement and purchase decisions.
Synthetic Data Generation
Researchers in autonomous driving and computer vision can add objects like pedestrians, vehicles, or traffic signs to existing scenes for training datasets, helping improve AI model performance in various scenarios.
Creative Arts and Design
Artists and designers can experiment with object placement and composition, exploring creative possibilities by adding elements to photographs or digital artworks while maintaining realistic integration.
Performance and Validation
Human Evaluation Results
- • Preferred in over 80% of user evaluations
- • Superior performance across image quality metrics
- • Better instruction following compared to baseline methods
- • Improved preservation of source image characteristics
Benchmark Performance
- • State-of-the-art results on Emu-Edit Benchmark
- • Superior performance on Additing Benchmark
- • Leading scores on Additing Affordance Benchmark
- • Outperforms supervised learning methods
Advantages and Considerations
Advantages
- No training requirements or fine-tuning needed
- Works with existing pretrained diffusion models
- Natural object placement with affordance understanding
- Preserves original image structure and details
- High success rate across diverse image types
- Professional-quality results from simple text inputs
- Supports both real and AI-generated images
Considerations
- Performance may vary with highly complex scenes
- Requires clear and specific text descriptions
- Processing time depends on image complexity
- Results may need iteration for optimal placement
- Best results achieved with appropriate prompt design
Frequently Asked Questions
Ready to Try Add-it AI?
Experience the future of image editing with intelligent object insertion. Try the interactive demo above or explore the research and code repositories.